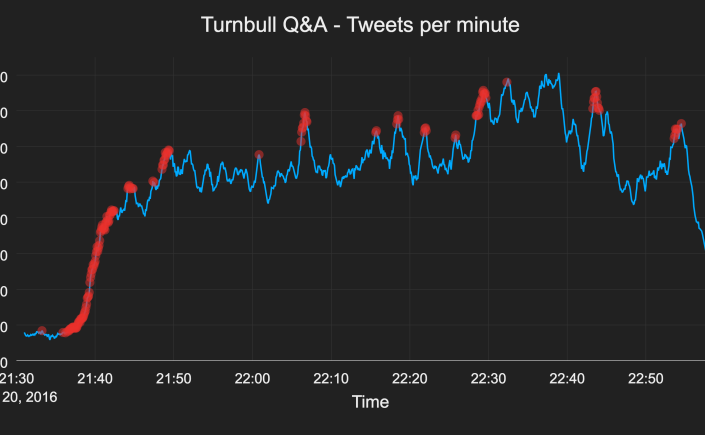
In August this year, I gave a talk at NDC Sydney on Real-time Twitter Analysis with Reactive Extensions. NDC is the Norway Developers Conference, so it’s a natural progression for them to come to Sydney. This was their first time down under, but they’ve already announced they’ll be back in August 2017.
It was a three day conference with over 100 speakers, some international and some local. That’s a lot of speakers, and it translates into 7 parallel tracks, or 7 concurrent talks.
Full talk video and code online
The video of my talk is on NDC’s vimeo channel, and the code and data driving the visualizations in the talk is on github. The repository is fairly large because the data files total a couple of hundred megabytes.
I’ve written a few articles covering parts of the material in the talk and discussing the code approach:
- Detecting spikes in real-time data
- Tracking Twitter discussion topics in real-time
- Analysing the Twitter reaction to Hillary Clinton’s and Barack Obama’s speeches at the 2016 Democratic National Convention.