

Princeton’s Algorithms II course includes an assignment on finding Boggle words. Briefly, Boggle is a game where you have a two dimensional grid of random letters and players try to find as many real words as they can from the board by stringing together neighbouring letters.
This post looks at how tweaking the initial implementation can give a 2x speedup, but picking the right data structure gives a 4,200x speedup.
Finding all words in a board
The assignment is to find all the valid words, given a board and a set of valid words. The initial problem is working out how to create a list of candidate words and check if they’re in the dictionary. Typically this leads to a recursive approach which wanders through the board trying each letter followed by each of its neighbours, followed by each of their neighbours, etc.
Here’s an example of making the valid word “pins” from a board:
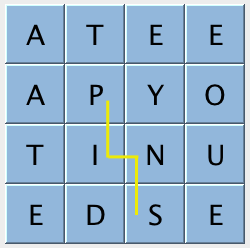
Make it snappy
However, the real crux of the assignment isn’t creating code that can find all the words, it’s creating something that can do it quickly. I haven’t heard of anyone needing to solve Boggle at scale but for this assignment, that’s our task.
The automarker for this assignment is a hard task master. It runs your solution on as many boards as it can for 5 seconds, and rates your solution against their reference, which averages around 6,000 boards per second.
So let’s take a look at a few different approaches and see how they rate.
Approach #1 – brute force
Performance: 1.06 boards/sec
Words tested: ~12 million
This is the approach above, with nothing done to aid performance. Our target is 6,000 boards per second, so it’s fair to say we’re missing the goal by a reasonable margin. The automarker is helpful and quantifies by exactly how much it’s better than us:
Test 2: timing getAllValidWords() for 5.0 seconds using dictionary-yawl.txt
(must be <= 2x reference solution)
- reference solution calls per second: 6359.14
- student solution calls per second: 1.06
- reference / student ratio: 5985.74
Ok, we’re out by a factor of 5,985. I appreciate the brutal honesty, it’s like being on If You Are The One:

It seems we’re going to have to do something fairly major in order to get some love from the automarker. The assignment spec basically gives you carte blanche to do whatever you want in order to improve speed, which is different from other assignments where you’re often tightly monitored on memory usage.
What’s wrong with brute force?
While the brute force approach above works, and even runs in a tolerable amount of time for normal cases, it’s no match for an automarker with high standards.
By searching neighbours of neighbours we end up with an exponential algorithm, and we don’t stop trying new letters on the end of the word until we run out of neighbours to try. So, the worst case word candidates will use every letter on the board, in every possible arrangement. It’s very unlikely that any of these candidates will be real words. It’s not even likely that any word longer than 10 or so letters will be valid. Appending a new letter to “AAPYNU” isn’t likely to make anything better.
So really the brute force approach doesn’t actually map very well to the problem of hunting out valid dictionary words from the board.
Preprocessing the dictionary
The real problem here is that the exponential search space through the board is immensely larger than the number of valid words in the dictionary. The brute force approach on a 4×4 grid of letters evaluates 12 million distinct paths, but there are only ~264,000 words in the test dictionary. The vast majority of all those distinct paths are going to be a complete waste of time.
Earlier I mentioned that we end up tracing through words that start with a prefix that no real word starts with. If we can prune the evaluation tree as soon as we hit such a prefix, we can save a lot of time. But having our set of dictionary words in a hash table doesn’t let us do that kind of a prefix search. We need a data structure better suited to this task – a trie.
With a basic trie, we store a node per letter of each word, but there are variants that are more sophisticated. Here’s an example of a simple trie from Wikipedia.
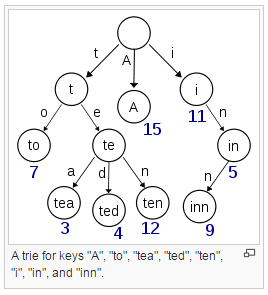
If we build a trie out of the dictionary, we can traverse each word in the dictionary one letter at a time. That lets us search the dictionary for a partial word – if we find a null node before we get to the end of the word prefix, we know that there’s no point searching further from this path through the board.
Approach #2 – using a trie
Performance: 4,900 boards/sec
Words tested: 2,848
Wow. Just by pre-processing the dictionary into a trie structure, we’re able to cut the search space down from 12 million potential words to 2,848, an improvement of a factor of ~4,200. The performance measured in boards solved per second has increased to 4,900 boards/sec. It’s no coincidence that the boards/sec has improved by almost the same factor as we’ve shrunk the search space by.
At this point, the automarker is happy enough to give us a pass on the performance tests. But we still haven’t actually matched the reference solution’s performance, we’re just within a tolerable range. We didn’t come all this way just to take the first sign of success and run!
The basic trie approach I implemented searches the dictionary for each possible word from the root of the trie each time. So in the above example, if the solver is evaluating the letters “TE”, it searches from the root, through each letter. Then we check “TEA”, and it searches again starting from the first letter. We already know “TE” is a valid prefix, we only need to search the next letter we’re evaluating.
Approach #3 – stepping through the board and trie in sync
Performance: 6,577 boards/sec
Instead of checking if the whole current word we’re looking at is a valid prefix each time we add a new letter, we can keep track of where we’re up to in the trie, and check if the next letter on the board is a valid next letter in the dictionary from where we are.
We get approximately a 30% improvement in the automarker results from this approach, which is enough to beat the reference solution.
Solving the right problem
My first cut of the brute force approach used string concatenation to build candidate words, and there are 12 million such candidate words in a 4×4 board. So obviously doing this many string concatenations (in Java) is going to lead to performance problems. I could have profiled the code, which no doubt would have pointed the finger at the string concatenation, and any other inefficiencies in my implementation.
Removing the string concatenation yielded a 2x speedup. That’s great, right? But switching to use a trie for the dictionary immediately yielded a 4,200x speedup.
No amount of micro optimisations on the wrong implementation are going to get anywhere near a better algorithm here. A profiler can show you where your code is taking lots of time, but it can’t look at your algorithm and tell you that you’re approaching the problem the wrong way.
So I’ll finish up with some wise words from the master. Not Bob Sedgewick, but Kunu from Forgetting Sarah Marshall. When it comes to performance, the less you do, the more you do.
